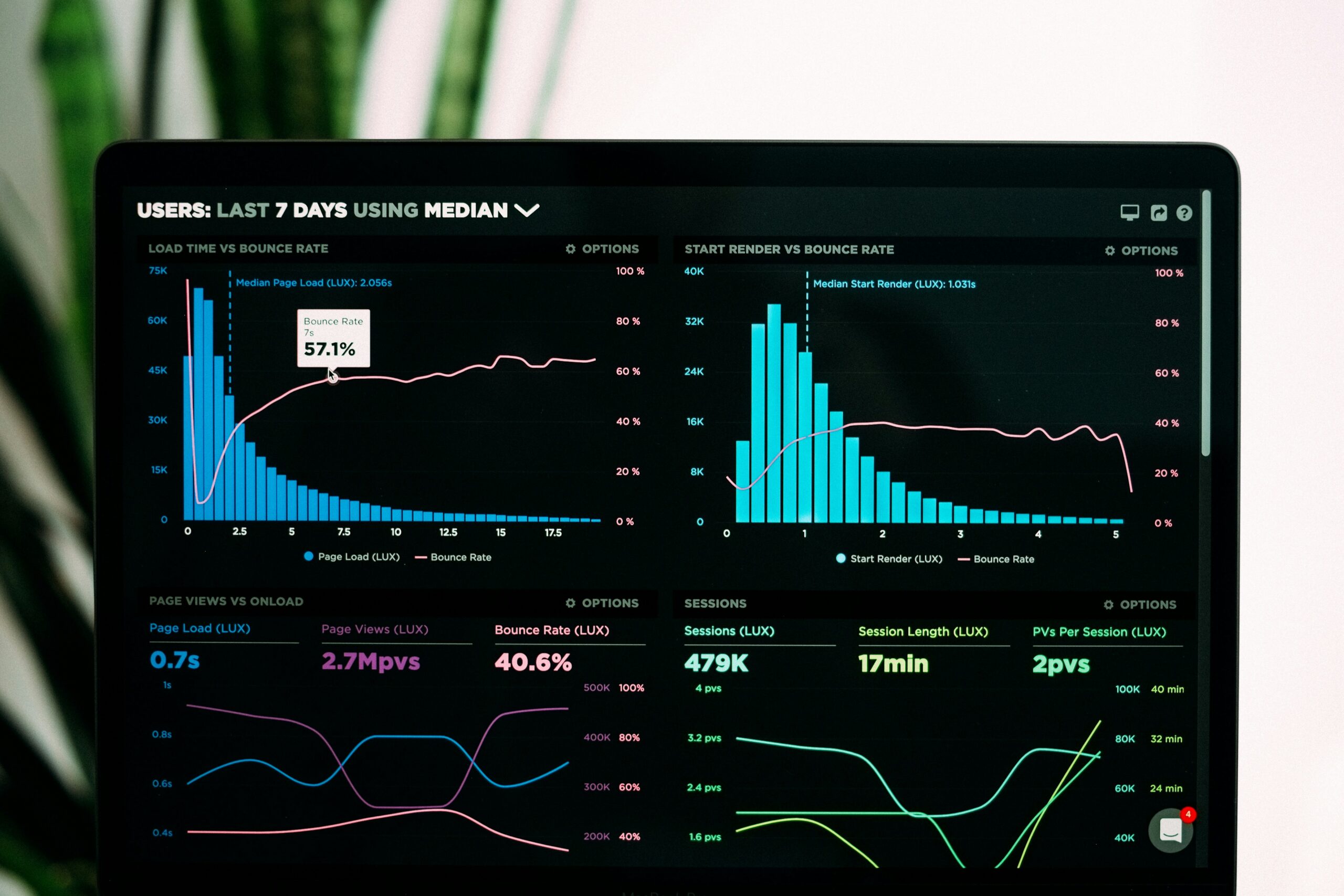
Introduction to Data Analysis in Machine Learning
Data analysis is a critical process in the field of machine learning, serving as the foundational step for building robust and effective models. At its core, data analysis involves examining raw data to uncover patterns, anomalies, and underlying structures that are essential for predictive modeling. This step is indispensable because the quality and comprehensiveness of data analysis directly influence the performance and accuracy of machine learning models.
The primary objective of data analysis in machine learning is to transform raw data into insightful information. This transformation involves several activities such as data cleaning, data integration, and exploratory data analysis (EDA). Data cleaning addresses issues like missing values and outliers, ensuring the dataset is reliable. Data integration merges data from various sources to provide a cohesive dataset, while EDA employs statistical and graphical techniques to summarize the main characteristics of the data.
Analyzing data before model training is crucial for several reasons. First, it helps to identify and rectify data quality issues that could skew model results. Second, it allows for the detection of significant variables and relationships that can enhance model accuracy. Third, it aids in understanding the distribution and variability of the data, which informs the selection of appropriate machine learning algorithms and techniques.
Furthermore, well-analyzed data has a profound impact on model performance. Models trained on thoroughly analyzed data tend to generalize better to new, unseen data, thereby improving their predictive capabilities. In contrast, models built on poorly analyzed data are more prone to overfitting, underfitting, and other issues that compromise their effectiveness.
In summary, data analysis is a pivotal step in the machine learning pipeline. By meticulously analyzing data, practitioners can ensure that their models are both reliable and accurate, ultimately leading to more meaningful and actionable insights.
Data Collection and Preprocessing
Data collection and preprocessing are foundational steps in the data analysis process, particularly within the realm of machine learning. The initial phase involves gathering relevant data from various sources such as databases, APIs, web scraping, or publicly available datasets. Ensuring the data’s quality and consistency is paramount, as it directly influences the effectiveness of the subsequent analysis.
Once the data is gathered, preprocessing begins, addressing issues such as missing values, which are common in raw datasets. Techniques like mean imputation, median imputation, or using algorithms designed to handle missing data can be employed to mitigate this problem. Data normalization is another critical step, where numerical values are scaled to a standard range, typically between 0 and 1, to ensure that no single feature dominates the learning process. This step helps in improving the performance and stability of machine learning models.
Data transformation techniques are also essential in making the data suitable for analysis. This might involve converting categorical data into numerical formats using methods like one-hot encoding or label encoding. Additionally, feature engineering, which involves creating new features from existing ones, can enhance model performance by providing more relevant information to the learning algorithm.
Another crucial aspect of preprocessing is splitting the dataset into training, validation, and test sets. This division helps in unbiased model evaluation and prevents overfitting. The training set is used to train the model, the validation set to tune the model’s parameters, and the test set to assess the model’s performance on unseen data. Typically, the data is split in such a way that the training set comprises about 60-70% of the data, the validation set 10-20%, and the test set 10-20%.
In conclusion, data collection and preprocessing are vital steps in the data analysis pipeline. Properly executed, they ensure that the dataset is clean, consistent, and ready for the next stages of data analysis in machine learning, leading to more accurate and reliable predictive models.
Exploratory Data Analysis (EDA) in Data analysis
Exploratory Data Analysis (EDA) is a critical step in the data analysis process, particularly within the realm of machine learning. EDA serves the primary function of understanding the underlying patterns, trends, and relationships within a dataset. By employing a variety of techniques and tools, EDA allows data scientists to gain insights that inform subsequent stages of the machine learning workflow.
Key techniques in EDA include summary statistics, which provide a high-level view of the data. Summary statistics such as mean, median, mode, and standard deviation offer insights into the central tendency and variability of the data. These metrics are fundamental in identifying any anomalies or outliers that may exist.
Data visualization methods are also indispensable in EDA. Histograms, scatter plots, and box plots are commonly used to visualize data distributions and identify patterns. Histograms allow for the examination of the distribution of a single variable, while scatter plots are useful for understanding relationships between two continuous variables. Box plots, on the other hand, offer a visual summary of the minimum, first quartile, median, third quartile, and maximum values, making it easier to detect outliers.
Correlation analysis is another pivotal aspect of EDA. This technique involves calculating correlation coefficients to quantify the degree of relationship between variables. Understanding correlations helps in identifying which features may be relevant for predictive modeling and which ones might be redundant. For instance, a high positive or negative correlation between two variables may indicate that one of them could be excluded from the model to avoid multicollinearity.
The importance of EDA in the machine learning process cannot be overstated. It helps in identifying potential issues such as missing values, data entry errors, and outliers that could adversely affect model performance. Moreover, EDA informs feature selection and engineering, guiding the creation of models that are both accurate and robust.
Feature Engineering and Selection
Feature engineering and selection are pivotal processes in data analysis within the realm of machine learning. These techniques are instrumental in enhancing model performance by refining the input data to create more predictive and efficient models.
Feature engineering involves transforming raw data into meaningful features that can be better understood by machine learning algorithms. This process can include creating new features based on existing data, encoding categorical variables, and scaling numerical features. For instance, creating interaction terms between variables or generating polynomial features can uncover hidden relationships in the data. Encoding categorical variables using methods like one-hot encoding or label encoding ensures that the model can interpret non-numeric data effectively. Scaling numerical features, such as standardizing or normalizing, helps in bringing all features to a comparable scale, which is crucial for algorithms that rely on distance metrics.
Feature selection, on the other hand, focuses on identifying the most relevant features to be used in the model. This step is essential to avoid overfitting, reduce computational cost, and improve model interpretability. Several techniques can be employed for feature selection, such as correlation matrices, which help in identifying highly correlated features that might be redundant. Mutual information measures the dependency between variables and can be used to select features that have a significant relationship with the target variable. Additionally, feature importance scores derived from models like Random Forest provide insights into which features contribute most to the model’s predictions.
Effective feature engineering and selection play a crucial role in data analysis in machine learning, leading to more accurate and efficient models. By carefully crafting and selecting features, data scientists can ensure that their models are not only predictive but also computationally less intensive, enhancing both performance and efficiency.