
Convolution operation in Convolutional Neural Networks
Convolutional Neural Networks (CNNs) have revolutionized the field of computer vision and are widely used for tasks such as image classification, object detection, and image segmentation. At the heart of CNNs lies the convolution operation, a fundamental concept that plays a crucial role in extracting meaningful features from input data.
What is Convolution?
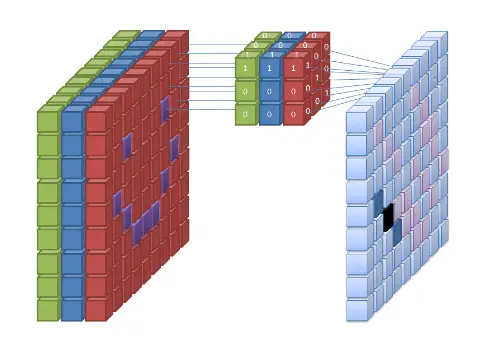
Convolution is a mathematical operation that combines two functions to produce a third function. In the context of CNNs, convolution is used to apply a filter ( kernel) to an input image. The filter is a small matrix of weights that is convolved with the input image to produce a feature map.
Each element of the feature map is computed by taking the dot product of the filter and a corresponding patch of the input image. This process is repeated for every patch in the image. It results in a new feature map that captures local patterns and structures.
Why is Convolution Important?
Convolution is a key operation in CNNs because it allows the network to automatically learn and extract relevant features from images. By applying different filters, a CNN can learn to detect edges, textures, and higher-level features such as shapes and objects.
Moreover, convolution helps reduce the computational complexity of the network. Instead of connecting every neuron to every pixel in the input image, convolutional layers only connect neurons to local patches. It significantly reduces the number of parameters and enabling the network to scale to larger images.
Convolutional Layers in CNNs
In a CNN, convolutional layers are responsible for performing the convolution operation. These layers consist of multiple filters that slide over the input image, producing a set of feature maps. Each filter captures different aspects of the input, allowing the network to learn diverse and hierarchical representations.
The size of the output feature maps depends on several factors, including the size of the input image, the size of the filters, and the padding and stride used during the convolution operation. The padding adds extra pixels around the input image, while stride determines the amount by which the filter moves across the image.
Typically, CNN architectures stack multiple convolutional layers to capture increasingly complex features. The output of each convolutional layer is often passed through an activation function, such as ReLU, to introduce non-linearity and enhance the network’s ability to learn complex patterns.
FAQs about Convolution in CNNs
Q: What is the purpose of the filter in convolution?
The filter in convolution is used to extract specific features from the input image. By convolving the filter with the image, the network can learn to detect edges, textures, and other relevant patterns.
Q: How does convolution reduce the computational complexity of CNNs?
Convolution reduces the computational complexity of CNNs by connecting neurons to local patches of the input image instead of every pixel. This significantly reduces the number of parameters and enables the network to process larger images efficiently.
Q: How are convolutional layers stacked in CNN architectures?
In CNN architectures, convolutional layers are stacked to capture increasingly complex features. Each layer applies multiple filters to the input, producing a set of feature maps. The output of each layer is often passed through an activation function to introduce non-linearity.
Q: What is the role of padding and stride in convolution?
Padding and stride are parameters that control the size of the output feature maps in convolutional layers. Padding adds extra pixels around the input image, while stride determines the amount by which the filter moves across the image. These parameters affect the spatial dimensions of the feature maps.
Q: Can convolution be applied to other types of data?
While convolution is commonly used in CNNs for image processing, it can also be applied to other types of data, such as audio signals or time series. In these cases, the input and filters are typically one-dimensional instead of two-dimensional.
Convolution is a powerful operation that lies at the core of CNNs. By understanding how convolution works and its importance in feature extraction, we can appreciate the remarkable capabilities of CNNs in the field of computer vision.