
When it comes to image processing in the Convolution neural network (CNN), the first step is to understand how the network perceives and analyzes the visual information. CNNs are designed to mimic the human visual system, which means they hierarchically process images, starting from low-level features and moving towards high-level features.
The first layer in a CNN is typically a convolutional layer. This layer consists of multiple filters or kernels, each of which is responsible for detecting a specific feature in the input image. Each filter slides over the entire image, performing a mathematical operation called convolution. This operation involves multiplying the values of the filter with the corresponding pixel values in the image and summing them up to produce a single value, known as the activation.
After the convolution operation, a non-linear activation function is applied to introduce non-linearity into the network. This allows the network to learn complex patterns and relationships in the image data. Common activation functions used in CNNs include the Rectified Linear Unit (ReLU) and the hyperbolic tangent (tanh) function.
The next step in image processing is pooling or subsampling. This step helps to reduce the spatial dimensions of the feature maps obtained from the convolutional layer, making the network more computationally efficient. The most commonly used pooling operation is max pooling, which selects the maximum value within a certain window and discards the rest.
Once the pooling operation is complete, the resulting feature maps are fed into another convolutional layer, and the process is repeated. This allows the network to learn more complex and abstract features as it progresses through the layers.
Finally, after several convolutional and pooling layers, the feature maps are flattened into a one-dimensional vector and passed through fully connected layers. These layers are similar to those in a traditional neural network and are responsible for making predictions based on the learned features.
Overall, the image processing in CNNs involves a series of operations, including convolution, activation, pooling, and fully connected layers. These operations allow the network to extract meaningful features from the input image and make accurate predictions for various computer vision tasks.
Step 1: Image Processing
The first step in processing an image in a Convolutional Neural Network (CNN) is to provide the input image. This image can be in various formats such as JPEG, PNG, or any other image format. The input image is a matrix of pixels, where each pixel represents the color or intensity value of a specific location in the image.
Before the image can be fed into the CNN, it undergoes a preprocessing step. This step involves resizing the image to a standard size, such as 224×224 pixels, to ensure that all images in the dataset have the same dimensions. Additionally, the image may be normalized to have zero mean and unit variance, which helps in improving the convergence of the network during training.
Basic Workflow of CNN
Once the preprocessing is complete, the image is ready to be passed through the network. The CNN consists of multiple layers, each performing a specific operation on the input image. These layers include convolutional layers, pooling layers, and fully connected layers.
The convolutional layers are responsible for extracting features from the input image. They use a set of learnable filters to convolve over the image and produce feature maps. Each filter detects a specific pattern or feature in the image, such as edges or textures. By applying multiple filters, the CNN can capture different types of features at different spatial scales.
The pooling layers, on the other hand, reduce the spatial dimensions of the feature maps while retaining the most important information. This helps in reducing the computational complexity of the network and makes it more robust to variations in the input image. The most commonly used pooling operation is max pooling, which selects the maximum value within a small window and discards the rest.
Finally, the fully connected layers take the flattened feature maps and perform classification or regression tasks. These layers are similar to the ones in a traditional neural network and are responsible for making predictions based on the extracted features. The output of the fully connected layers is usually passed through an activation function, such as softmax or sigmoid, to produce the final output probabilities.
Step 2: Convolution
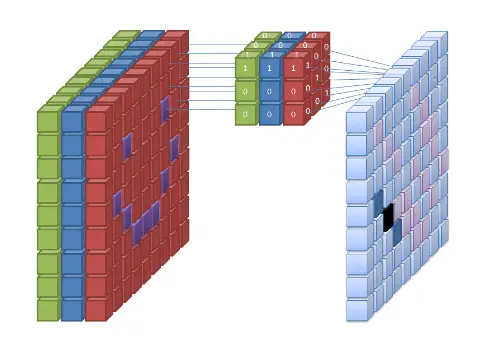
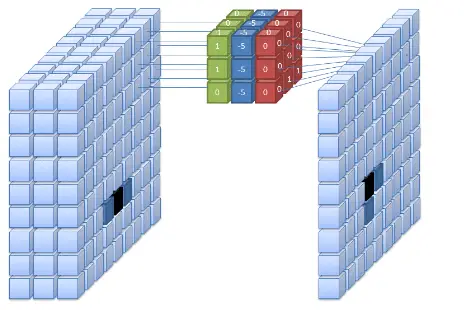
The convolution operation is the core building block of a CNN. It involves applying a set of learnable filters or kernels to the input image. Each filter is a small matrix of weights that is convolved with a part of the input image. The convolution operation helps in extracting local features from the image by computing the dot product between the filter and the corresponding image patch.
During the convolution operation, the filter is slid over the entire input image, and at each position, the dot product is computed. This results in a feature map, which represents the presence or absence of certain features in the input image. The size of the feature map depends on the size of the input image, the size of the filter, and the stride value (the number of pixels by which the filter is shifted after each convolution operation).
The choice of filters is crucial in determining what kind of features the CNN can learn. For example, if the task is to classify images of cats and dogs, the filters might learn to detect edges, textures, and patterns that are characteristic of cats and dogs. These learned features are then used to distinguish between the two classes.
Convolutional neural networks are designed to exploit the spatial structure of the input data. By using shared weights in the filters, CNNs can effectively capture local patterns regardless of their position in the image. This property makes CNNs particularly well-suited for tasks such as image recognition, object detection, and semantic segmentation.
Overall, the convolution operation is a fundamental step in the training and inference process of a convolution neural network learning. It allows the network to extract meaningful features from the input data, which are then used for making predictions or performing other tasks. The effectiveness of the convolutional operation, combined with the other layers in a CNN, has led to significant advancements in the field of computer vision and has enabled the development of state-of-the-art models for various applications.
Step 3: Non-linear Activation
After the convolution operation, a non-linear activation function is applied to introduce non-linearity into the network. The most commonly used activation function in CNNs is the Rectified Linear Unit (ReLU). ReLU sets all negative values in the feature map to zero, while keeping the positive values unchanged. This helps in enhancing the important features and suppressing the irrelevant ones.
However, ReLU is not the only activation function used in convolution neural network. There are several other activation functions that can be used depending on the requirements of the problem. One such activation function is the Sigmoid function, which squashes the input values between 0 and 1. This is particularly useful in binary classification problems, where the output needs to be interpreted as a probability.
Another commonly used activation function is the Hyperbolic Tangent (Tanh) function. Similar to the Sigmoid function, Tanh also squashes the input values, but between -1 and 1. This makes it suitable for problems where the output needs to be in the range of -1 to 1, such as sentiment analysis or speech recognition.
In addition to these commonly used activation functions, there are also other variants such as the Leaky ReLU, Parametric ReLU, and Exponential Linear Units (ELUs), each with its own advantages and disadvantages. The choice of activation function depends on the specific problem being solved and the desired properties of the network.
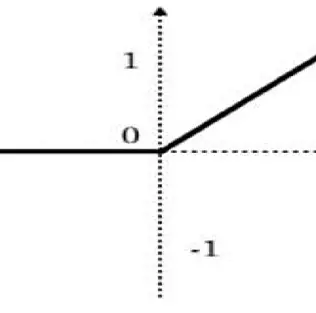
Regardless of the specific activation function used, the purpose of applying a non-linear activation function is to introduce non-linearity into the network. Without non-linear activation, the network would be limited to learning only linear relationships between the input and output. By introducing non-linearity, the network becomes capable of learning more complex patterns and relationships, making it more powerful and capable of solving a wider range of problems.
Step 4: Pooling
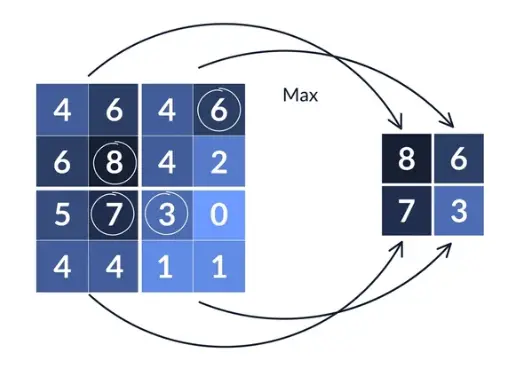
Pooling is a downsampling operation that reduces the spatial dimensions of the feature map. It helps in reducing the computational complexity and extracting the most important features. The most commonly used pooling operation is max pooling, where the maximum value within a pooling window is selected and the rest are discarded. This results in a smaller feature map with reduced spatial dimensions.
During the pooling operation, a pooling window slides over the feature map, dividing it into non-overlapping regions. Each region is then reduced to a single value, which represents the most salient feature within that region. This process is repeated for every region in the feature map, resulting in a downsized feature map.
Max pooling is particularly effective in capturing the most dominant features of an image. By selecting the maximum value within each pooling window, it ensures that only the most significant information is retained. This is crucial for reducing the computational complexity of the network and preventing overfitting.
Another commonly used pooling operation is average pooling, where the average value within each pooling window is computed. This can be useful in scenarios where the average intensity or value of a feature is more important than the maximum value.
By reducing the spatial dimensions of the feature map, pooling helps in capturing higher-level features and patterns. This is especially beneficial for tasks such as image classification, where the overall structure and composition of an image are more important than the precise pixel values.
Overall, pooling plays a crucial role in the success of deep learning models. It helps in reducing the computational complexity, extracting important features, and improving the generalization ability of the network. By downsampling the feature map, pooling enables the network to focus on the most relevant information, leading to more efficient and accurate predictions.
Step 5: Fully Connected Layers
After the convolutional and pooling layers, the processed image features are flattened into a vector and passed through one or more fully connected layers. These layers are similar to the layers in a traditional neural network and help in capturing higher-level features and making predictions. Each neuron in the fully connected layer is connected to all the neurons in the previous layer, which allows for learning complex patterns and relationships.
In the fully connected layers, the flattened feature vector is multiplied by a weight matrix and passed through an activation function. The weight matrix contains the learnable parameters of the model, and the activation function introduces non-linearity into the network. This non-linearity is crucial for the model to learn complex patterns and make accurate predictions.
The number of neurons in the fully connected layers is typically much larger than the number of neurons in the convolutional layers. This allows the model to capture a wide range of features and relationships between different parts of the image. Additionally, the fully connected layers often have dropout layers inserted between them. Dropout is a regularization technique that randomly sets a fraction of the inputs to zero during training, which helps prevent overfitting and improves the generalization ability of the model.
Output layer in convolution neural network
After passing through the fully connected layers, the output is then fed into the final layer of the network, which typically consists of a softmax activation function. This final layer converts the output of the previous layers into a probability distribution over the different classes or categories that the model is trained to predict. The class with the highest probability is then considered as the predicted class for the input image.
Overall, the fully connected layers play a crucial role in the deep learning model by capturing higher-level features and making predictions based on these features. They allow the model to learn complex patterns and relationships in the input data, enabling it to make accurate predictions in various tasks such as image classification, object detection, and segmentation.
The output layer plays a crucial role in the overall performance of the convolution neural network. It is the final stage where the network makes predictions and provides the desired output. The number of neurons in the output layer is determined by the specific task at hand. In classification tasks, the number of neurons in the output layer corresponds to the number of classes that the network needs to classify the input data into. Each neuron in the output layer represents the probability of the input image belonging to a particular class.
During the training phase, the CNN learns to adjust the weights and biases of the neurons in the output layer in order to minimize the difference between the predicted output and the ground truth. This process, known as backpropagation, involves iteratively updating the parameters of the network based on the error between the predicted output and the actual output.
Once the CNN has been trained, it can be used to make predictions on new, unseen data. The input image is fed into the network, and the activations of the neurons in the output layer are computed. The neuron with the highest activation represents the predicted class for the input image.
It is important to note that the output layer of a CNN can be customized based on the specific requirements of the task. For example, in some cases, multiple neurons in the output layer may be activated, indicating that the input image belongs to multiple classes simultaneously. This is known as multi-label classification. Additionally, the output layer can be modified to include additional information, such as bounding box coordinates or segmentation masks, depending on the nature of the task.
In conclusion, the output layer is a critical component of a CNN, responsible for making predictions based on the learned features. It determines the number of neurons based on the task at hand and provides the final output of the network. Through the process of backpropagation, the network learns to adjust the parameters of the output layer to minimize the difference between the predicted output and the ground truth. The output layer can be customized to suit the specific requirements of the task, allowing for flexibility in the predictions made by the CNN.
Frequently Asked Questions (FAQs)
Q1: Can CNNs process images of any size?
A1: CNNs can process images of any size, but they typically require resizing or cropping the input images to a fixed size. This is done to ensure that all images have the same dimensions, which is necessary for the convolution and pooling operations.
However, it is important to note that the fixed size chosen for the input images can have an impact on the performance of the CNN. If the chosen size is too small, important details in the images may be lost, leading to a decrease in accuracy. On the other hand, if the chosen size is too large, the computational cost of processing the images may become prohibitive.
To address this issue, various techniques have been developed to handle images of different sizes. One common approach is to use image resizing techniques such as bilinear or bicubic interpolation to scale the images to the desired size. These techniques preserve the overall structure and content of the image while adjusting its dimensions.
Another approach is to use image cropping, where a portion of the image is selected and used as the input. This can be useful when the object of interest in the image is relatively small compared to the overall image size. By cropping the image to focus on the object, the CNN can extract more relevant features and improve its performance.
In addition to resizing and cropping, some CNN architectures have been designed to handle images of arbitrary sizes without the need for preprocessing. These architectures, such as Fully Convolutional Networks (FCNs), utilize techniques like spatial pyramid pooling or dilated convolutions to adapt to different input sizes. These methods allow the CNN to effectively process images of varying dimensions while maintaining the spatial information and improving performance.
Overall, while CNNs can theoretically process images of any size.
Q3: What is the purpose of the pooling operation in a convolution neural network?
A3: The pooling operation helps in reducing the spatial dimensions of the feature map and extracting the most important features. It also helps in making the network more robust to variations in the input image, such as translation and rotation.
Pooling is an essential step in convolutional neural networks (CNNs) that plays a crucial role in feature extraction and dimensionality reduction. After convolutional layers, the feature map obtained contains a large number of spatial dimensions, which can be computationally expensive to process. The pooling operation addresses this issue by downsampling the feature map, reducing its size while retaining the most important information.
By reducing the spatial dimensions, pooling also helps in achieving translation invariance. Translation invariance means that the network can recognize an object regardless of its position within the image. This is particularly important in tasks like object detection and recognition, where the location of the object may vary. Pooling allows the network to focus on the presence of certain features rather than their exact location.
In summary, the purpose of the pooling operation in CNNs is to reduce the spatial dimensions of the feature map, extract the most important features, achieve translation invariance, and enhance the network’s robustness to variations in the input image. This step plays a critical role in improving the efficiency and effectiveness of CNNs in various computer vision tasks.
Q4: Are fully connected layers necessary in a convolution neural network(CNN)?
A4: Fully connected layers are not always necessary in a convolution neural network. In some cases, the convolutional and pooling layers alone can be sufficient for making predictions. However, fully connected layers are often added to capture higher-level features and make more complex predictions.
Fully connected layers, also known as dense layers, are typically used in the final stages of a convolutional neural network (CNN) architecture. These layers are responsible for taking the output from the previous layers and mapping it to the desired number of classes or labels. They are called “fully connected” because each neuron in the previous layer is connected to every neuron in the fully connected layer.
The convolutional and pooling layers capture low-level features like edges and textures, but they may not be sufficient to capture more complex relationships and semantic information. This is where fully connected layers come into play.
By connecting every neuron in the previous layer to the fully connected layer, these layers can learn to recognize more global patterns and relationships in the data. They can combine the low-level features extracted by the earlier layers and create a representation that is more suitable for making predictions. This is especially useful in tasks that require understanding the context or overall structure of the input data.
For example, in an image classification task, the convolutional and pooling layers can detect edges, textures, and other local features. However, they may not be able to capture the spatial relationships between these features or understand the overall composition of the image. Fully connected layers can learn to recognize higher-level features like shapes, objects, or even entire scenes, which can greatly improve the accuracy of the model.
In conclusion, while fully connected layers are not always necessary in a convolution neural network, they play a crucial role in capturing higher-level features and making more complex predictions. They allow the model to learn global patterns and relationships in the data, which can greatly improve its performance in tasks that require understanding the context or overall structure of the input. Additionally, fully connected layers provide a flexible framework for incorporating prior knowledge or domain-specific information into the model, making them a valuable component in CNN architectures.
Q5: What is the role of the activation function in a convolution neural network?
A5: The activation function introduces non-linearity into the network and helps in learning complex patterns and relationships. It helps in enhancing the important features and suppressing the irrelevant ones.
When it comes to the activation function, it is important to note that different types of activation functions can be used in a CNN. One commonly used activation function is the Rectified Linear Unit (ReLU), which replaces negative values with zero and keeps positive values unchanged. The ReLU activation function has been found to work well in many deep-learning applications, including image classification and object detection.
Another popular activation function is the sigmoid function, which maps the input values to a range between 0 and 1. This function is particularly useful in binary classification tasks, where the output needs to be interpreted as a probability. The sigmoid function can also be used in multi-class classification problems by applying it to each class independently.
Choosing the right activation function for a specific task is crucial as it can greatly impact the performance of the convolution neural network. It is important to consider factors such as the nature of the problem, the desired output range, and the potential limitations of different activation functions.
In summary, the activation function in a convolution neural network plays a vital role in introducing non-linearity, enhancing important features, and suppressing irrelevant ones. Understanding the different types of activation functions and their characteristics is essential for effectively designing and training CNNs for image-processing tasks.